#include <stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
通过 gcc -o helloworld helloworld.c来编译得到helloworld可执行程序。
通过 ./helloworld来执行程序:
$ ./00_helloworld
hello world
通过 mpiexec -n 4 helloworld来执行程序:
$ mpiexec -n 4 00_helloworld
hello world
hello world
hello world
hello world
$ mpiexec -n 2 00_helloworld
hello world
hello world
#include <stdio.h>
#include <mpi.h>
int main(int argc, char **argv)
{
MPI_Init(&argc, &argv);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int my_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
printf("MPI_COMM_WORLD size: %d, My Rank : %d\n", world_size, my_rank);
MPI_Finalize();
return 0;
}
注意:因为MPI_Init()函数要求有参数,故main函数的参数列表不能为空。
$ mpicc -o 01_startup 01_startup.c
$ ls
00_helloworld 00_helloworld.c 01_startup 01_startup.c
$ mpiexec -n 4 ./01_startup
MPI_COMM_WORLD size: 4, My Rank : 0
MPI_COMM_WORLD size: 4, My Rank : 1
MPI_COMM_WORLD size: 4, My Rank : 3
MPI_COMM_WORLD size: 4, My Rank : 2
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#define LENGTH 64000000
int main(int argc, char **argv)
{
int world_size, my_rank;
double start_time, end_time;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
double *a, *b, *c;
// init a
start_time = MPI_Wtime();
a = (double *)malloc(LENGTH * sizeof(double));
for (int i = 0; i < LENGTH; i++)
a[i] = 1.0;
end_time = MPI_Wtime();
if (my_rank == 0)
printf("init a time : %f\n", end_time - start_time);
// init b
start_time = MPI_Wtime();
b = (double *)malloc(LENGTH * sizeof(double));
for (int i = 0; i < LENGTH; i++)
b[i] = 2.0;
end_time = MPI_Wtime();
if (my_rank == 0)
printf("init b time : %f\n", end_time - start_time);
// c = a + b
start_time = MPI_Wtime();
c = (double *)malloc(LENGTH * sizeof(double));
for (int i = 0; i < LENGTH; i++)
c[i] = a[i] + b[i];
end_time = MPI_Wtime();
if (my_rank == 0)
printf("c = a + b time : %f\n", end_time - start_time);
// sum c
start_time = MPI_Wtime();
double sum = 0;
for (int i = 0; i < LENGTH; i++)
sum += c[i];
end_time = MPI_Wtime();
if (my_rank == 0)
printf("sum = %f, sum c time : %f\n", sum, end_time - start_time);
free(a);
free(b);
free(c);
MPI_Finalize();
return 0;
}
mpicc -o 02_question 02_question.c来编译;./02_question和 mpiexec -n 4 02_question来观察结果。如果内存足够大,两种运行方式得到的结果相差不大,因为后者相当于将代码拷贝四份分别运行在四个进程中,执行着完全相同的函数,故而时间上不会有什么变化。但如果内存不大,可能后者还会更慢,因为后者所占的内存更多,或许会涉及到swap。
$ ./02_question
init a time : 0.281029
init b time : 0.262633
c = a + b time : 0.306716
sum = 192000000.000000, sum c time : 0.172745
$ mpiexec -n 2 02_question
init a time : 0.299567
init b time : 0.277720
c = a + b time : 1.305820
sum = 192000000.000000, sum c time : 0.73616
在上述的例子中,要想加快程序的运行速度,并行计算的思想是把数组a、b、c分块给不同的进程来处理,而后再合并到一起。这需要用到消息传递,即将数组分块并通过消息传递给其他的进程,核心函数是 MPI_Send()和 MPI_Recv()。
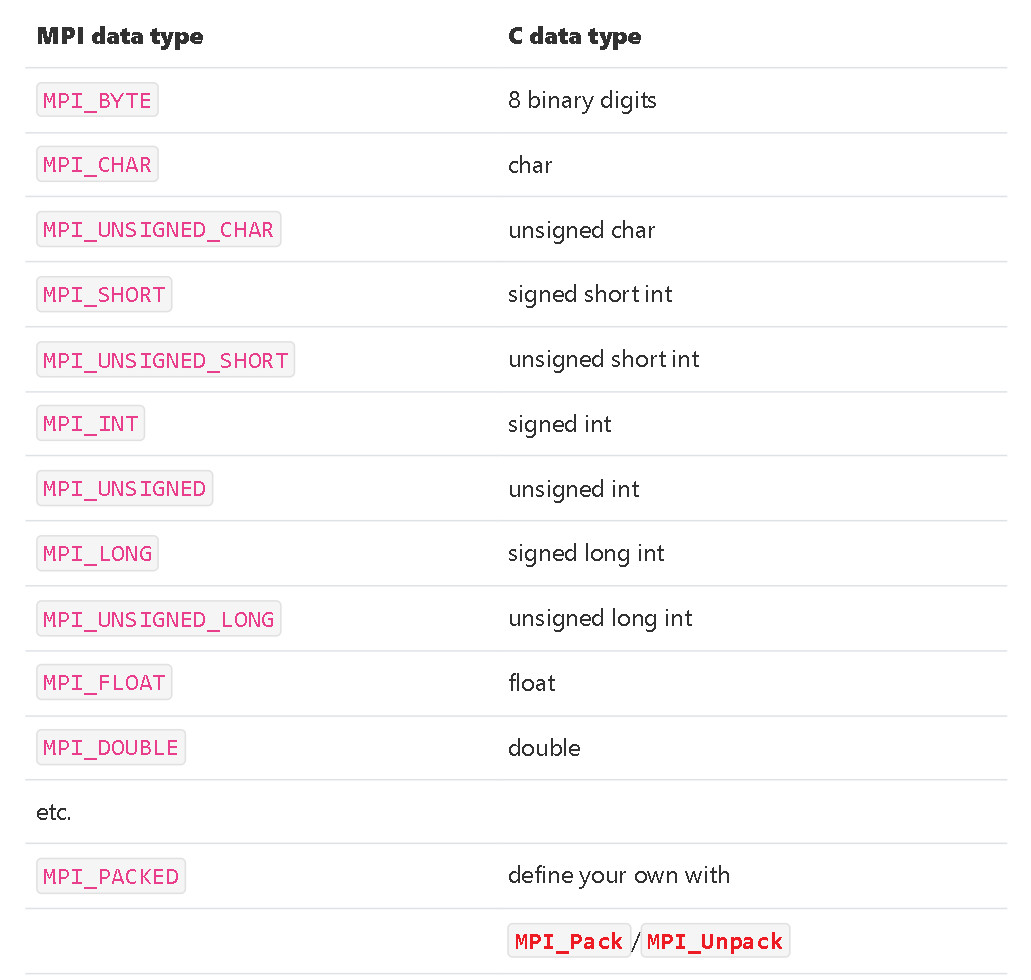
int MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm);
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status);
通过借助这两个函数,把a数组的初始化、b数组的初始化、c数组的计算以及求和部分并行化,得到如下程序:
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#define LENGTH 64000000
int main(int argc, char **argv)
{
int world_size, my_rank;
double start_time, end_time;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
// calculate workloads[worldsize]
int my_start = 0, my_end = 0, workloads[world_size];
for (int i = 0; i < world_size; i++)
{
workloads[i] = LENGTH / world_size;
if (i < LENGTH % world_size)
workloads[i]++;
}
// calculate my start and end
for (int i = 0; i < my_rank; i++)
my_start += workloads[i];
my_end = my_start + workloads[my_rank];
double *a, *b, *c;
// init a
start_time = MPI_Wtime();
a = (double *)malloc(workloads[my_rank] * sizeof(double));
for (int i = 0; i < my_end - my_start; i++)
a[i] = 1.0;
end_time = MPI_Wtime();
if (my_rank == 0)
printf("init a time : %f\n", end_time - start_time);
// init b
start_time = MPI_Wtime();
b = (double *)malloc(workloads[my_rank] * sizeof(double));
for (int i = 0; i < my_end - my_start; i++)
b[i] = 2.0;
end_time = MPI_Wtime();
if (my_rank == 0)
printf("init b time : %f\n", end_time - start_time);
// c = a + b
start_time = MPI_Wtime();
c = (double *)malloc(workloads[my_rank] * sizeof(double));
for (int i = 0; i < my_end - my_start; i++)
c[i] = a[i] + b[i];
end_time = MPI_Wtime();
if (my_rank == 0)
printf("c = a + b time : %f\n", end_time - start_time);
// sum c
start_time = MPI_Wtime();
double sum = 0;
for (int i = 0; i < my_end - my_start; i++)
sum += c[i];
// point to point communicate
if (my_rank == 0)
{
for (int i = 1; i < world_size; i++)
{
double partial_sum;
MPI_Status status;
MPI_Recv(&partial_sum, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &status);
sum += partial_sum;
}
}
else
{
MPI_Send(&sum, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
end_time = MPI_Wtime();
if (my_rank == 0)
printf("sum = %f, sum c time : %f\n", sum, end_time - start_time);
free(a);
free(b);
free(c);
MPI_Finalize();
return 0;
}
运行结果明显快于./02_question,但因为消息传递有代价,故而运行时间比和进程数比小:
$ ./02_question
init a time : 0.275963
init b time : 0.262448
c = a + b time : 0.307388
sum = 192000000.000000, sum c time : 0.174510
$ mpiexec -n 2 03_p2pcomm
init a time : 0.151625
init b time : 0.145042
c = a + b time : 0.176536
average = 192000000.000000, average c time : 0.086219
$ mpiexec -n 4 03_p2pcomm
init a time : 0.087089
init b time : 0.069351
c = a + b time : 0.092179
average = 192000000.000000, average c time : 0.094953
上述所说的点对点通信是一对一的进程间通信,而接下来要介绍的是多对多的进程间通信,这极大简化了代码。
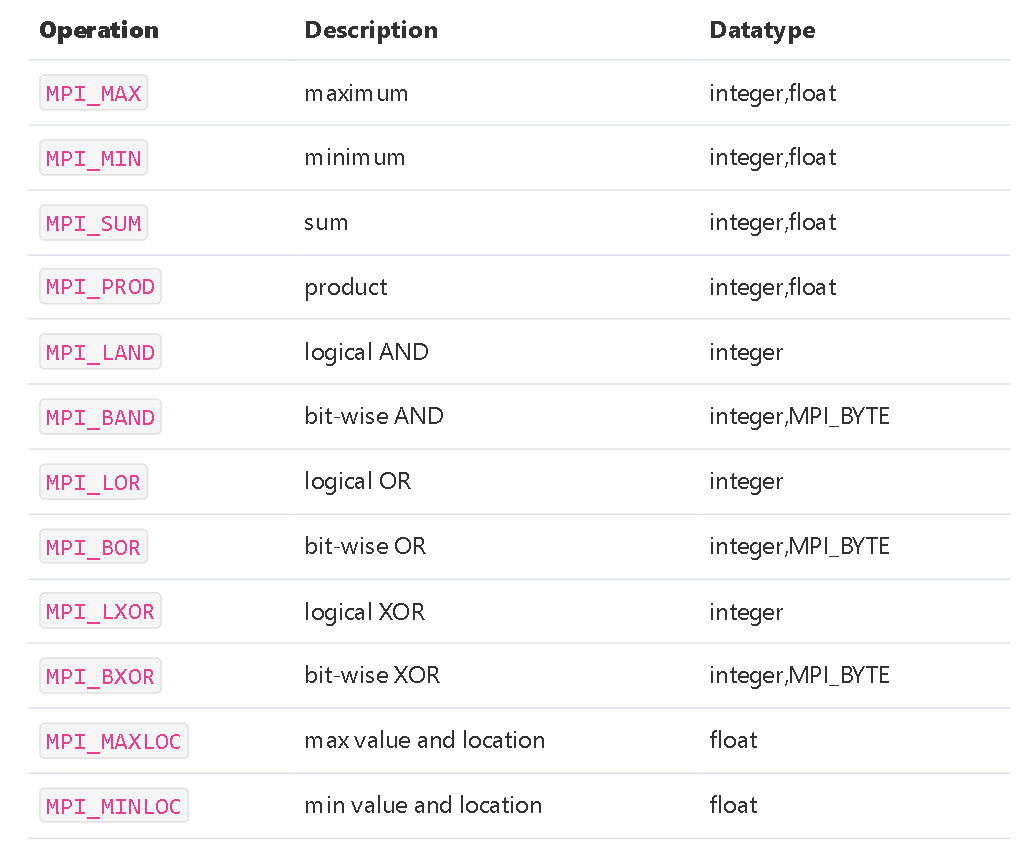
int MPI_Reduce(const void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
把原来// point to point communicate这一部分的代码改为下面的:
// collective communicate
double partial_sum = sum;
MPI_Reduce(&partial_sum, &sum, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
除此之外,还有一些其他接口可供使用,可以在实际编程中相应进行查询,比如:
// MPI_Bcast:用于初始化、全局配置同步
// MPI_Scatter:将数据拆分后发给各进程
// MPI_Scatterv:支持指定拆分方式
// MPI_Gather:汇总计算结果
// MPI_Alltoall:发送部分数据,并接受数据
// MPI_Reduce:规约操作
// MPI_Allreduce:规约操作,结果返回给所有进程
// MPI_Reduce_scatter:先规约后分散
{kind=link}
{kind=link}