PaperReading
SyzDirect
Linux内核DGF模糊测试工具,给定某个位置,对该位置进行stress-test。
难点
- 如何确定触发该位置的syscall;
- 如何确定触发该位置的syscall的参数值。
解决方案
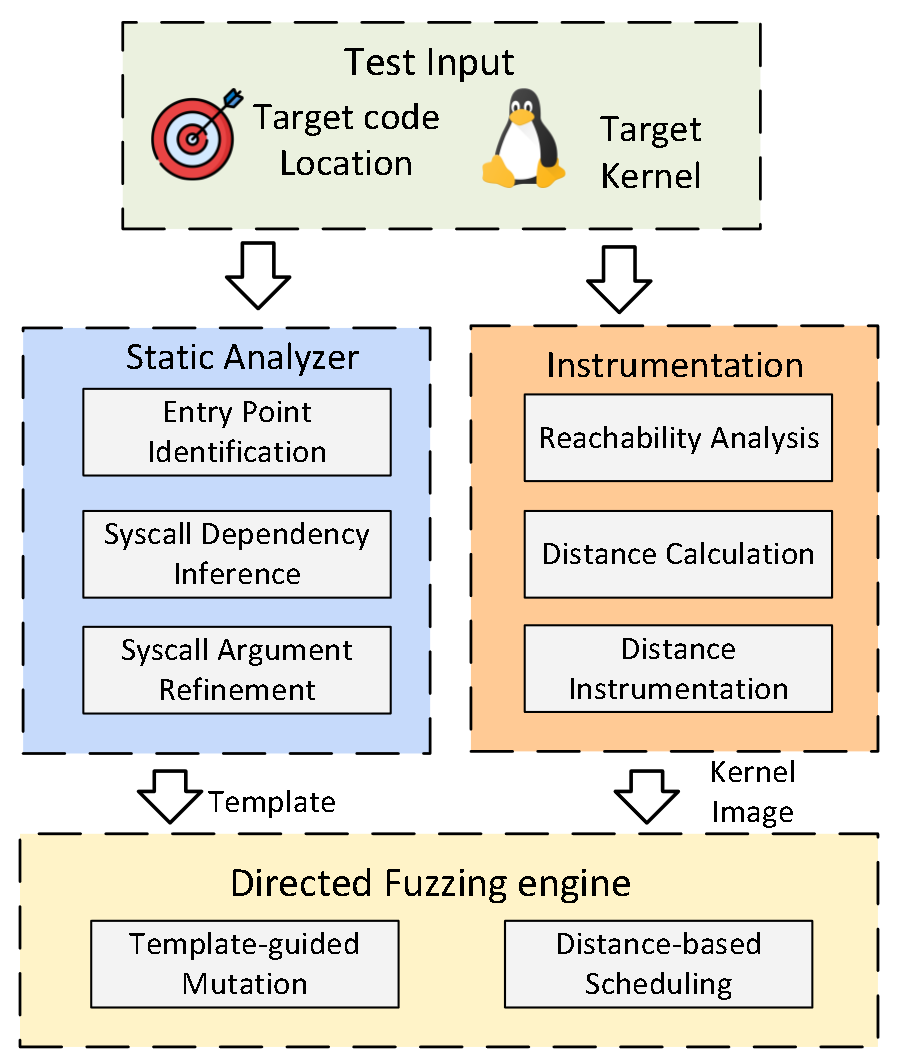
- Entry Point Identification:从target入手,得到调用链,分析用到的资源,结合这些信息,筛选可能的目标syscall。即kernel function和syscall的对应,用到了syzlang;
- Syscall Dependency Inference:得到和目标syscall相依赖的syscall,从资源的创建和使用方面来入手,这个在syzlang里面提供了;
- Syscall Argument Refinement:syscall确定后,就会根据条件语句确定系统调用的参数,这个也要结合syzlang;
- Directed Kernel Fuzzing:得到上述信息后,会用来指导种子变异,定制了变异规则;
细节
Entry Point Identification
建模思路
这一部分的目标是找到能够触发目标代码位置(target code location)的系统调用变体(syscall variants),也叫做入口系统调用(entry syscalls)。为了实现这个目的,需要将内核函数(kernel functions)和系统调用变体对应起来。因为相比于原始系统调用(primitive syscalls),系统调用变体的粒度更细,即记录了在特定资源上的特定操作,故而将内核函数与系统调用变体匹配,而不是原始系统调用。具体的匹配方法是用相同的方式对内核函数和系统调用变体的操作和资源建模。
建模步骤
对于内核函数而言,并不是所有的内核函数都显式的给出资源和操作,所以没法直接获得。但是,当一个系统调用被执行时,在内核里,会进行函数分发(function dispatch),即根据系统调用参数来决定要处理的资源和要执行的操作。所以可以通过观察函数分发的过程,来分析内核函数要操作的资源以及具体操作。这里把函数分发过程后的第一个函数当作锚函数(anchor function),首先对锚函数进行建模并匹配系统调用变体,除了锚函数之外的函数会被对应到可以到达该函数的锚函数,并与锚函数的系统调用变体进行匹配。
操作建模
原始系统调用一般是对应多个操作,内核会根据传入的参数来决定具体执行哪个操作。因此,用系统调用名称和参数来对操作进行建模。对于系统调用变体,可以直接从syzlang的表述中提取系统调用名称,然后将数字常量参数作为要建模的参数。对于内核函数,给定一个原始系统调用,进行控制流分析得到CFG并关注switch语句,进行数据流分析以判断switch的变量是否和参数相关,对于那些和参数相关的switch语句,会把每个case中的内核函数当作锚函数,然后将系统调用名称和case后的常量作为要建模的参数。例子如图三。
{kind=link}
资源建模
因为操作的资源在内核函数或系统调用变体中可能被定义为不同的标识符,所以不能用资源的名称来建模,而应该用一些不变量来进行建模,用资源的类型。创建资源的时候会用到相应的字符串和常量参数,所以将创建过程中用到的字符串和常量参数来对资源建模。比如,对于文件和设备资源,在创建时需要指定路径;对于socket资源,需要family和socket type。
对于系统调用变体1而言,可以通过分析参数来确定要操作的资源,然后找到创建该资源的系统调用变体2,然后用系统调用变体2参数的字符串和常量值来对该资源进行建模。如果字符串是路径,则去掉前缀。例子如图四。
{kind=link}
对于内核函数而言,作者观察到不同的资源在内核中会有不同的类似虚表的数据结构,进入系统调用后,会通过间接调用来执行函数分发,间接调用会查询虚表来执行相应的内核函数。所以虚表里面的函数也被认为是锚函数,而这些锚函数所操作的资源就是虚表对应的资源。故而接下来聚焦于如何对虚表对应的资源进行建模,这一部分涉及人工,先不看了。
对于非锚函数的内核函数,会进行控制流分析来得到与之相关的锚函数,用这些锚函数的模型来表示该内核函数,然后在系统调用变体中找到拥有相同模型的,与之匹配。
确认入口
故,对于一个目标代码位置,会进行控制流分析找到能触发该目标代码位置的原始系统调用,然后对内核函数和系统调用变体建模,找到对应的系统调用变体。
Syscall Dependency Inference
除了确定可以触发目标代码位置的入口系统调用之外,还需要确定一些其他系统调用,即用来提供入口系统调用资源或设置内核状态的系统调用,称这些系统调用为相关系统调用(related syscalls)。通过对资源的创建和使用的分析,来确定相关系统调用。这里没有采用静态分析,而是采用动态分析。
通过适配Healer算法来找到与入口系统调用相关的相关系统调用。首先分析入口系统调用的参数并且提取参数类型,然后找到返回类型相同的系统调用。如果这样找到的相关系统调用太多的话,会只保留在同一内核模块的相关系统调用。
Syscall Argument Refinement
条件提取->条件匹配->参数描述优化:在内核函数中找到控制触发目标代码位置的条件语句,提取出常量;将提取出的常量与Syzlang中的参数描述做匹配;删掉那些与该常量无关的参数描述。
Distance Calculation and Instrumentation
先获得Linux内核的调用图Call Graph,然后针对目标位置分析每个函数的可达性,不可达则距离为无限大,可达则构建CFG得到基本块距离。
通过对KCOV进行修改,来先后计算三个距离,系统调用距离、种子距离、模板距离。模板包含多个种子,种子包含多个系统调用,系统调用包含多个路径,都取最短的路径。
Directed Kernel Fuzzing with Template Guidance
模板即系统调用变体和内核函数对,种子的变异会依据模板来进行,模糊测试的进行会依据距离来确定优先级。
语料库初始化也是根据模板来生成的;在种子选择时,优先选择距离小的,并且这些种子也更可能会变异。
总而言之,就是利用模板来进行测试。