"V" Standard Extension for Vector Operations
每一个支持向量扩展的hart,都有两个常量参数:
线程一般不会在具有不同VLEN的hart之间做上下文切换。
在寄存器方面,支持向量扩展的hart,会带有32个VLEN个bit宽的向量寄存器(v0-v31)和7个非特权csr寄存器。
mstatus[10:9]/sstatus[10:9]/vsstatus[10:9]是VS域,VS域有Off, Initial, Clean, Dirty四个状态:
- 如果VS是Off,那么执行向量指令/访问向量寄存器将是非法的;
- 执行任何改变向量状态的指令,VS域都会从Initial/Clean变成Dirty,软件可以据此来减少上下文切换开销。
注:VS域的维护可能不准确,所以一般不用来做是否减少上下文切换开销的依据?
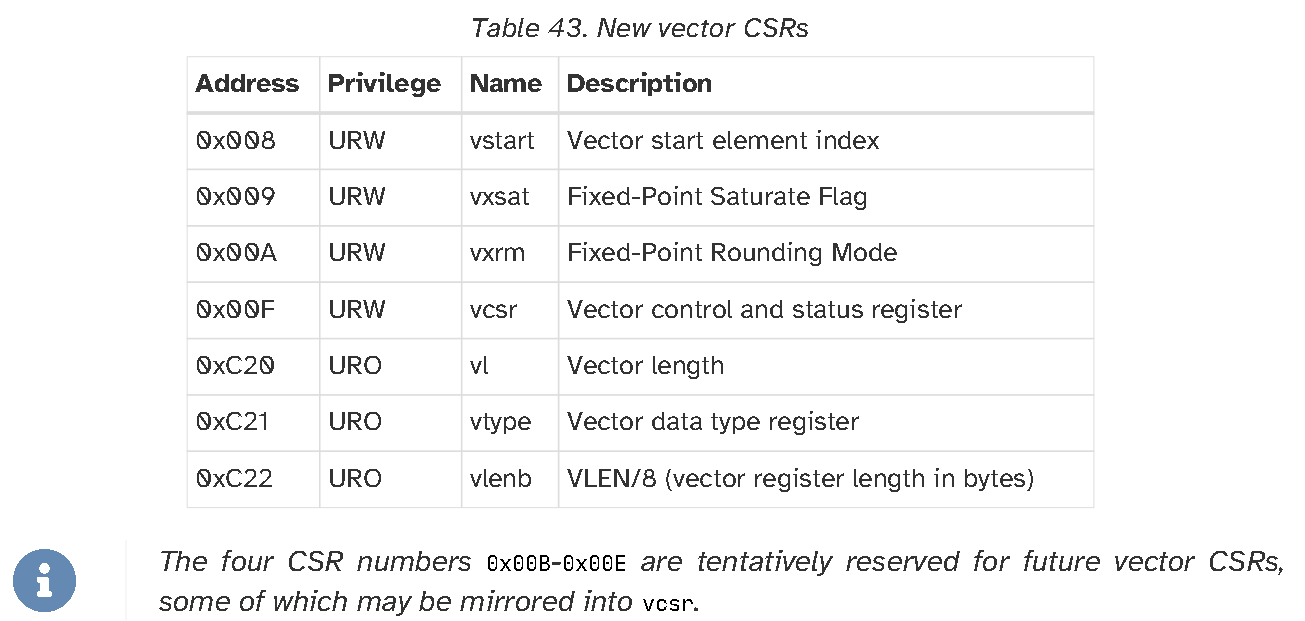
在手册里,有对7个csr寄存器的详细介绍,这里只简单说一下。
在V扩展里面,有几个值需要关注,它们分别是vtype.VSEW, vtype.VLMUL和VLEN,它们分别表示一个元素的位宽、一个寄存器组所拥有的寄存器数量和一个寄存器数量的位宽。
由于向量指令的操作数是一个寄存器组,所以想要搞清楚一个向量指令会作用于多少个位宽是多少的元素,势必要理解前面提到的三个值。下面会从vtype.VLMUL的角度出发,分三类说明:
关于Mixed-Width和Mask的更多信息见手册原文。
向量指令的操作数可以是向量寄存器,也可以是标量寄存器,且支持向量mask。
配置设置指令主要作用于vl和vtype寄存器,以此来设置VLMUL和VSEW的值。
下面通过一个具体的例子来学习,LLM来帮我理解:
# Example: Load 16-bit values, widen multiply to 32b, shift 32b result
# right by 3, store 32b values.
# On entry:
# a0 holds the total number of elements to process
# a1 holds the address of the source array
# a2 holds the address of the destination array
loop:
vsetvli a3, a0, e16, m4, ta, ma # vtype = 16-bit integer vectors;
# also update a3 with vl (# of elements this iteration)
vle16.v v4, (a1) # Get 16b vector
slli t1, a3, 1 # Multiply # elements this iteration by 2 bytes/source element
add a1, a1, t1 # Bump pointer
vwmul.vx v8, v4, x10 # Widening multiply into 32b in <v8--v15>
vsetvli x0, x0, e32, m8, ta, ma # Operate on 32b values
vsrl.vi v8, v8, 3
vse32.v v8, (a2) # Store vector of 32b elements
slli t1, a3, 2 # Multiply # elements this iteration by 4 bytes/destination element
add a2, a2, t1 # Bump pointer
sub a0, a0, a3 # Decrement count by vl
bnez a0, loop # Any more?
{kind=link}
{kind=link}
{kind=link}
{kind=link}